На форумах мы часто видим один и тот же вопрос: «как мне внутри формулы вычисляемого показателя определить то, что пользователь выбрал в такой-то иерархии?» или «как определить что пользователь выбрал на оси такой-то».
Ответ: штатными средствами - никак, потому что нету соотвествующих MDX функций, которые знают что у пользователя на клиенской стороне выбрано на строках, столбцах или в контексте.
Зато у нас в продукте эта проблема решается очень просто: при создании вычисляемой меры можно использовать виртуальные сеты. Покажем это на примерах.
Допустим, в выборке элементов у нас задано диапазон дат (то есть, набор элементов в иерархии Date.Calendar):
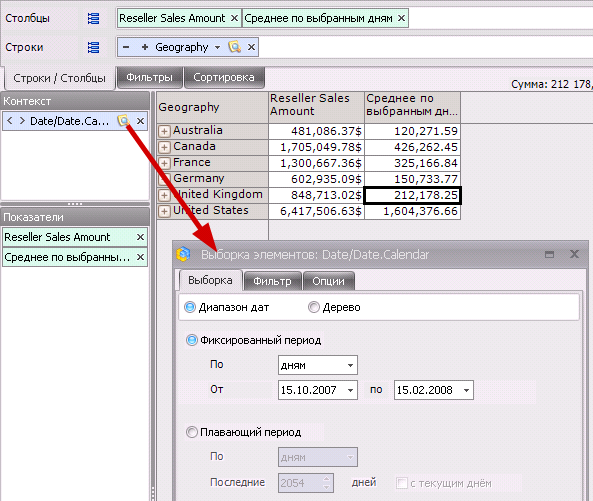
Допустим, мы хотим найти средние продажи по всем выбранным нами дням.
Для этого мы создаем формулу, которая выглядит так:
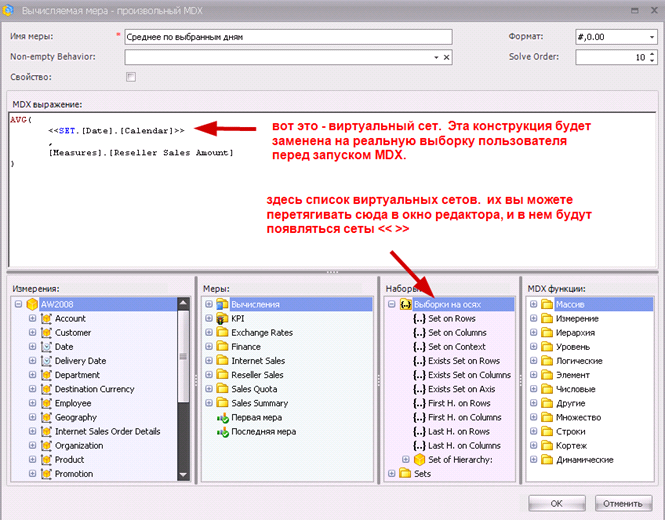
Как видно, формула MDX у нас имеет вид
AVG(
<<SET.[Date].[Calendar]>>
,
[Measures].[Reseller Sales Amount]
)
Но перед запуском ее на сервере виртуальный сет <<SET.[Date].[Calendar]>> будет заменен на его реальный эквивалент, таким образом мы получим такой MDX:
--========= MAIN =========--
WITH
MEMBER [Measures].[Среднее по выбранным дням] AS
AVG(
{[Date].[Calendar].[All].&[2007].&[2007]&[2].&[2007]&[4].&[2007]&[10].&[20071015]
:
[Date].[Calendar].[All].&[2008].&[2008]&[1].&[2008]&[1].&[2008]&[2].&[20080215]}
,
[Measures].[Reseller Sales Amount]
)
,FORMAT_STRING = '#,0.00'
,SOLVE_ORDER = 10
SELECT
NON EMPTY {
{[Measures].[Reseller Sales Amount],
[Measures].[Среднее по выбранным дням]}
} ON COLUMNS,
NON EMPTY {
{[Geography].[Geography].[Country].AllMembers}
} ON ROWS
FROM
(
SELECT
(
{[Date].[Calendar].[All].&[2007].&[2007]&[2].&[2007]&[4].&[2007]&[10].&[20071015]
:
[Date].[Calendar].[All].&[2008].&[2008]&[1].&[2008]&[1].&[2008]&[2].&[20080215]}
) ON COLUMNS
FROM [Adventure Works]
)
Все виртуальные сеты, которые имеют вид <<SET.Dimension.Hierarchy>> заменяются на выборку элементов пользователя в этой иерархии, независимо от того, где эта иерархия лежит – на строках, столбцах или в контексте.
Кроме них есть еще набор виртуальных сетов, таких как
<<SET.Rows>> - это весь кроссджойн, который лежит на строках:

Аналогично <<SET.Columns>> - это кроссджойн всего, что на столбцах, <<SET.Context>> - всего, что в контексте.
Кроме этих сетов еще бывает полезно в MDX формулах получить те сеты, которые принадлежать первым и последним иерархиям на строках/столбцах. Для этого служат вот эти четыре виртуальных сета:

А также бывает иногда полезным наши MDX формулы завязать на меру, которую пользователь смотрит в данный момент времени. То есть, сделать так, чтобы если пользователь выбрал сумму – то среднее считалось по сумме, а если он выбрал количество – то среднее считалось по количеству. Для таких целей служит вот это:

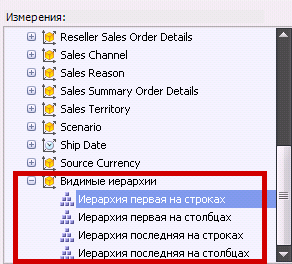
Также иногда бывает полезным использовать не сам сет, а только название иерархии, которая лежит на странице первой в списке. Для этого служат вот эти конструкции:
Мы пошли дальше. Сделали также несколько виртуальных функций:
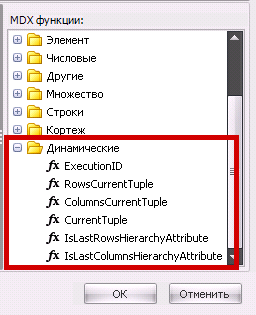
Функция <<CurrentTuple>>, например, будет заменена на реальный тупл
(D1.H1.CurrentMember, D2.H2.CurrentMember, …. , и здесь все другие иерархии.CurrentMemer) которые присутствуют в отчете на строках, столбцах или в контексте.
Очень часто нам надо писать формулы, которые вытягивают все «карренты» по всем иерархиям. Но проблема в том, что если на отчете одни иерархии – то надо писать одну конструкцию, а если другие – то другую. Получается зависимость формулы от вида отчета. Вот эта неудобность нас в один момент достала, и мы решили ее избавиться раз и навсегда путем введения <<CurrentTuple>>
Конструкции <<RowsCurrentTuple>> и <<ColumnsCurrentTuple>> - аналогичные, с той лишь разницей, что в тупле (h.CurrentMember, h2.CurrentMember… hn.CurrentMember) будут перечислены только те иерархии, которые перечислены на строках или столбцах отчета.
Конструкция <<ExecutionID>> заменяется на уникальный GUID – разный каждый раз, когда запускается запрос. Это полезно для сторед процедур на C#: если вы делаете свою процедуру, и хотите чтобы все ее вызовы из одного запуска отчета как-то видеть (с целью сделать общим для них какой-то буфер памяти), то эта штука будет очень полезной. Мы у себя иногда делаем пре-калькуляцию кое-каких данных внутри C# процедуры, и держим их в памяти. Но вызов ее – статический: когда приходит следующий ее вызов, мы не имеем понятия с какого отчета какого коннекта он идет… А как это разрулить? Понятно как: делается логика внутри процедуры, которая пишет это в хеш-таблицу с соотвествующим ключем, а следующие вызовы уже читают с этой таблицы. Мы видим что это вызов с того же отчета того же пользователя именно по переданному GUID. Память потом освобождаем через некоторое время – по таймауту. Но это уже другая тема, о которой мы обязательно напишем в следующий раз.
Удачи с использованием виртуальных сетов и конструкций!