In this article we'll show you one interesting approach which we discovered recently: we call it "surrogate attributes". It speeds up the performance of many calculated measures, especially those which run through dimension members of the lowest granularity level.
Let us look at the example:
SUM(
FILTER(
NonEmpty(
existing [Customer].[Customer].[Customer].Members
, [Measures].[Internet Sales Amount]
)
, [Measures].[Internet Order Quantity] >= 2
)
, [Measures].[Internet Order Count]
)
You may find that this measure is artificial. Yes, it is: I've done this measure on Adventure Works database just to demonstrate the approach. The goal is to calculate something by running on low-level objects.
In this example we need to find out how many orders made those customers whose quantity of ordered products is more than 2.
If we build a report like this
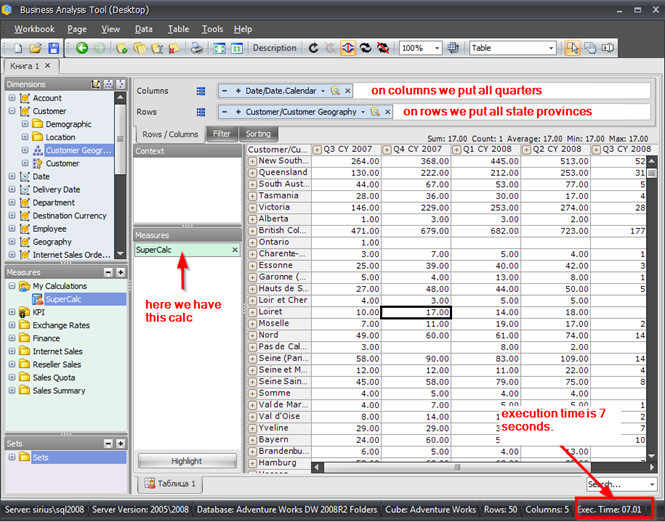
we'll get 7 seconds execution.
By analyzing the request in MDX Studio and looking at the performance counters, we found this:
- Time : 7 sec 607 ms
- Calc covers : 0
- Cells calculated : 43641
- Sonar subcubes : 4103
- NON EMPTYs : 995
- Autoexists : 6
- EXISTINGs : 2422
- SE queries : 2318
- Flat cache insert : 0
- Cache hits : 2649
- Cache misses : 2098
- Cache inserts : 982
- Cache lookups : 4747
- Memory Usage KB : 16884
43641 calculations, 4103 sonars, 2318 storage engine queries. If we look at some interesting performance counters in the case if we run a similar MDX request on a real customer's database, we notice this:
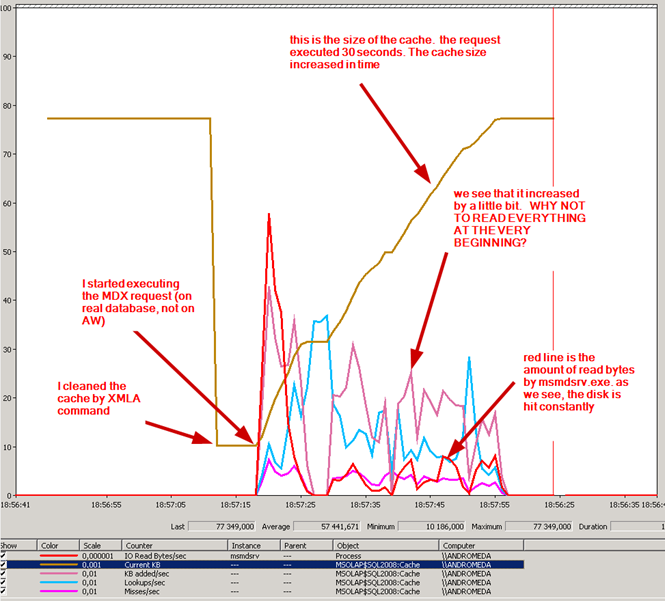
Unfortunately, there is no way to tell to the MSAS "please, read all the measuregroup into memory because you will need it WHOLE later." There is no such MDX or XMLA command.
So, what shall we do in this case? The answer is next: we need to improve our formula AND to add one trick to the dimension.
The construct "SUM(FILTER(set, condition), measure)" is a very ineffective one, and it should be replaced with "SUM(set, IIF(condition, measure, null))" to allow block evaluation working.
So, if we change the formula like this
SUM(
existing [Customer].[Customer].[Customer].Members,
IIF(
[Measures].[Internet Sales Amount] > 0
AND
[Measures].[Internet Order Quantity] >= 2,
[Measures].[Internet Order Count],
null
)
)
we will get much better performance:
- Time : 179 ms
- Calc covers : 0
- Cells calculated : 250
- Sonar subcubes : 72
- NON EMPTYs : 1
- Autoexists : 0
- EXISTINGs : 71
- SE queries : 159
- Flat cache insert : 0
- Cache hits : 285
- Cache misses : 0
- Cache inserts : 0
- Cache lookups : 285
- Memory Usage KB : 0
We can stop out optimization efforts, of course. But this is not enough: we run 159 storage engine queries instead of one, and I still don't like it.
Why this happens? Just because for every non-empty cell the set
existing [Customer].[Customer].[Customer].Members
is different. But how can we make so that this set is the same for every cell?
This can be done with the help of a trick: let us add a new attribute to the Customers dimension with the same key as the key attribute and with no specified name:
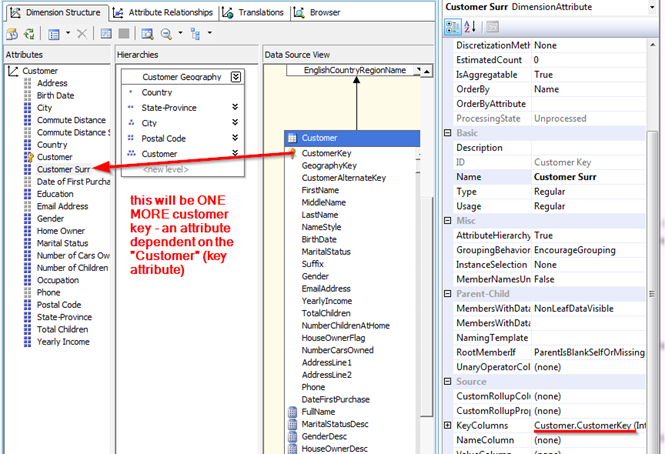
Process the cube, and rewrite the formula like this:
SUM(
[Customer].[Customer Surr].[Customer Surr].Members,
IIF(
[Measures].[Internet Sales Amount] > 0
AND
[Measures].[Internet Order Quantity] >= 2,
[Measures].[Internet Order Count],
null
)
)
Now look at the result:
- Time : 25 ms
- Calc covers : 0
- Cells calculated : 250
- Sonar subcubes : 1
- NON EMPTYs : 1
- Autoexists : 0
- EXISTINGs : 0
- SE queries : 3
- Flat cache insert : 0
- Cache hits : 3
- Cache misses : 0
- Cache inserts : 0
- Cache lookups : 3
- Memory Usage KB : 0
Isn't it impressive?
We've removed "existing" keyword because we did not need it any longer: the surrogate attribute evaluates to null in all those non-existing coordinates. So, if we look at this cell
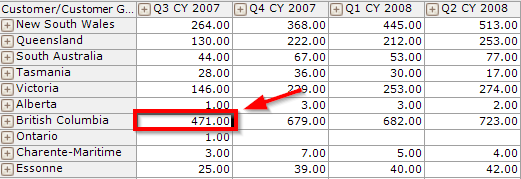
It will sum to
(British Columbila, Customer1_Surrogate, measure) +
(British Columbila, Customer2_ Surrogate, measure) +
. . . + (enumerated all customers) +
(British Columbila, CustomerN_ Surrogate, measure)
But for all those customers who do not belong to British Columbia, such tuples will automatically evaluate to null, because attributes "State-Province" and "Customer Surr" are INDEPENDENT on each other.
If you used the real dimension key (instead of surrogates) in the formula, then IT WOULD NOT EVALUATE TO NULL, because real key "vanishes" the British Columbia (because the "State-Province" is dependent on the real key). That is why real key attribute doesn't suit us.
Conclusion
We optimized everything from 7.6 seconds to 179 milliseconds – in 42.4 times, and we COULD STOP on this, but we did not. Instead, we made one more optimization – from 179 milliseconds to 25 milliseconds, that is in 7.16 more times.
On this example with Adventure Works this may seem as "not important". But believe me, on real huge databases this plays a big role.
From now we try to make surrogate attributes every time in every dimension, and we always consider using them instead of real keys in all calculations where we have enumeration of the values.
P.S.
You can get acquainted with our BI suite "Business Analysis Tool" at our website www.bitimpulse.com